Key Takeaways
- Model APIs are (mostly) stateless, so agents re-send their entire history on every call. A 40-step Viktor thread transmits ~2.17M input tokens even though the transcript is only ~85K tokens long.
- Prompt caching turns re-sent tokens into 0.1x cache reads. On Claude Opus 4.8 our example thread drops from $11.35 to $2.07, an 81.8% reduction.
- Caching only works if the prefix is byte-stable, so it has to shape the whole agent architecture: tools are exposed as SDK functions in code instead of schemas in the prompt, and every thread is an append-only log.
- Summarization runs inside the thread's own cache, sending the full history as a 0.1x read instead of paying full price in a separate call.
- Compaction timing follows the cache lifecycle: never compact a hot thread, compact aggressively in the minutes before the cache goes cold.
- Every provider's cache behaves differently (explicit breakpoints vs automatic, TTLs, routing), so the thread engine adapts per provider.
Viktor is an AI employee that lives in Slack and Microsoft Teams. People hand it real work: triage a support inbox, audit a CRM pipeline, analyze a QA screen recording, build a report. A single task routinely means a thread with dozens of model calls, each one carrying the system prompt, the user's skills and memory, the conversation so far, and a growing pile of tool results.
That workload shape has a brutal cost profile if you implement it naively. This post walks through the problem, the math, and the specific architectural decisions inside Viktor's thread engine that keep frontier-model agents economically viable. Everything below comes from our production codebase, and we will keep one concrete example thread running through every calculation, priced on Claude Opus 4.8.
1. The problem: LLM APIs have no memory
The mental model many people have of a chat with a model is a phone call: an open line where you only transmit the new things you say. The reality is closer to mailing the entire case file to a new consultant every time you have a follow-up question.
Model APIs are stateless (mostly: stateful options exist, but if you want to retain full control over what the model sees, you treat them as stateless). There is no session on the provider's side that remembers your conversation. Every single call must contain everything the model needs: the system prompt, the tool definitions, every prior user message, every assistant reply, every tool call and every tool result. When the model answers, you append its reply to your local transcript, and the next call re-sends all of it again, plus the new turn.
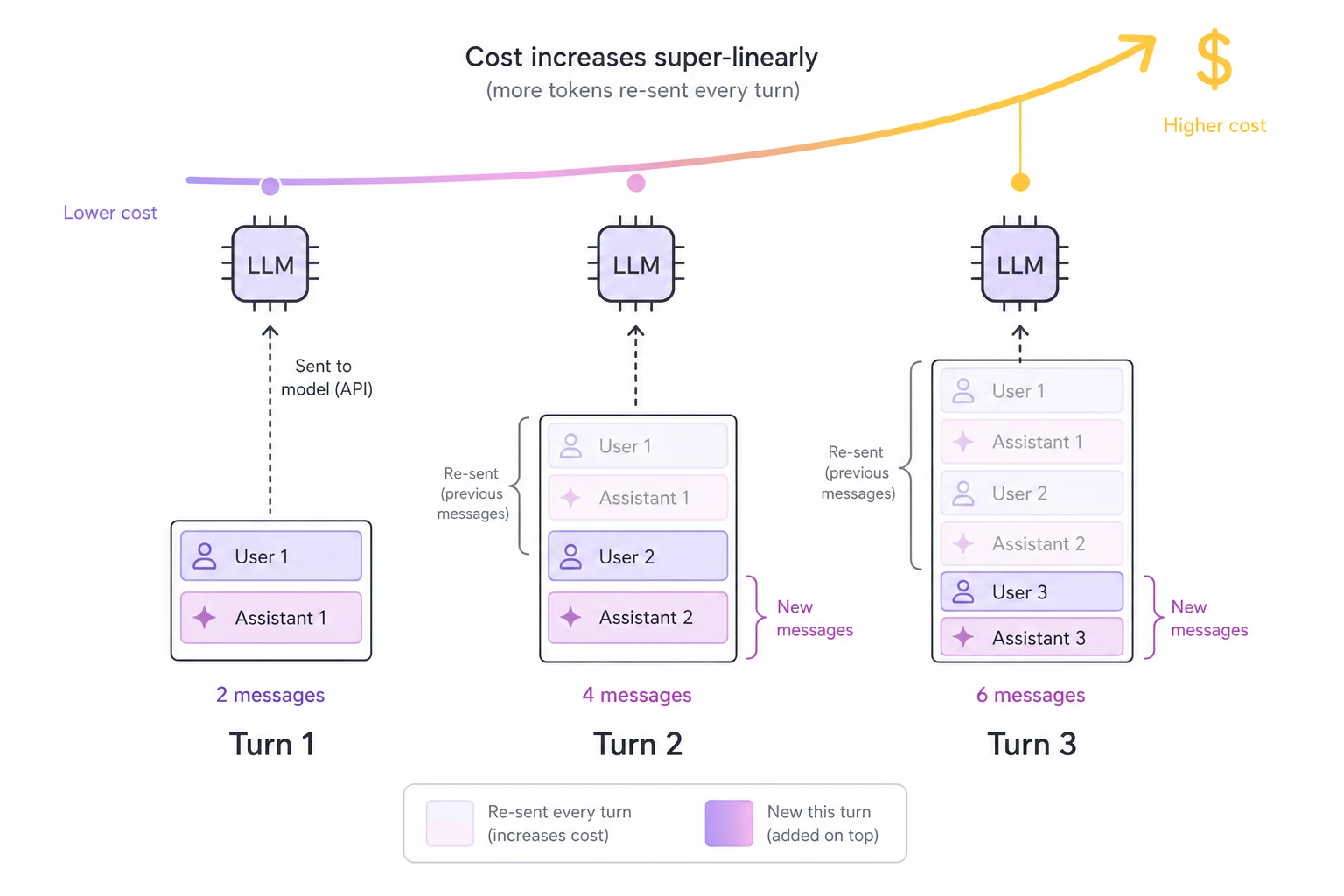
Every turn re-sends the entire history. The new tokens are the small part; the re-sent tokens dominate.
For a human chat with five short turns, this is irrelevant. For an agent it is the whole ballgame, because an agent loop is just a conversation with itself at machine speed: call the model, get a tool call, execute it, append the result, call the model again. Forty steps means forty full re-transmissions of an ever-growing transcript.
The cost of this grows quadratically. If your context starts at P tokens and each step appends s tokens, the total input tokens across N calls is roughly N·P + s·N²/2. Double the length of a task and you pay four times as much for the tail.
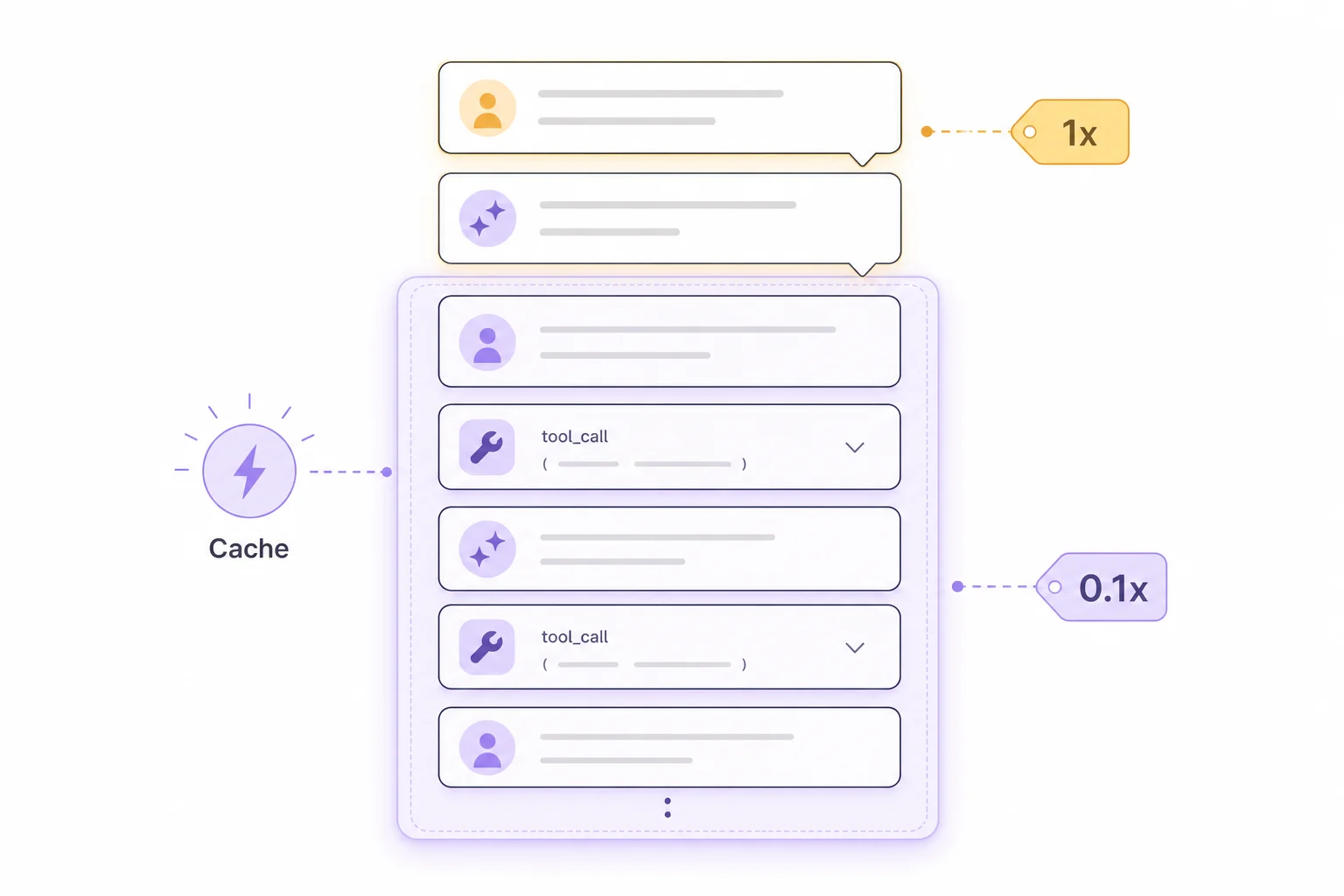
Our running example. A realistic Viktor thread: a 25,000-token stable prefix (system prompt, skills, tool definitions), 40 model calls, and each step appending ~1,500 tokens of tool calls and results. Total input transmitted across the thread: 2,170,000 tokens, even though the final transcript is only ~85,000 tokens long. You send the same early tokens up to 40 times.
2. Prompt caching changes the unit economics
Providers noticed that virtually all agent traffic looks like this: a long, byte-identical prefix plus a small new suffix. So they built prompt caching: the provider keeps the processed internal state (the KV cache) of your prompt prefix for a short time, and if your next request starts with the exact same bytes, it resumes from the cached state instead of recomputing it.
The discount is dramatic. Here is the pricing for Claude Opus 4.8, the model we run for most Viktor threads:
| Token type | Price / 1M tokens | vs. regular input |
| Regular input | $5.00 | 1× |
| Cache write (first time a prefix is stored) | $6.25 | 1.25× |
| Cache read (every subsequent hit) | $0.50 | 0.1× |
| Output | $25.00 | -- |
You pay a 25% premium once to write a prefix into the cache, and then every read of it costs a tenth of the normal price. In an agent loop where call N+1 re-sends everything from call N, nearly all input tokens become cache reads.
Run our example thread through both pricing modes:
| Cost component | No caching | With caching |
| Input at full price (2,170,000 tok × $5/M) | $10.85 | -- |
| Cache writes (83,500 tok × $6.25/M) | -- | $0.52 |
| Cache reads (2,086,500 tok × $0.50/M) | -- | $1.04 |
| Output (20,000 tok × $25/M) | $0.50 | $0.50 |
| Total for the thread | $11.35 | $2.07 |
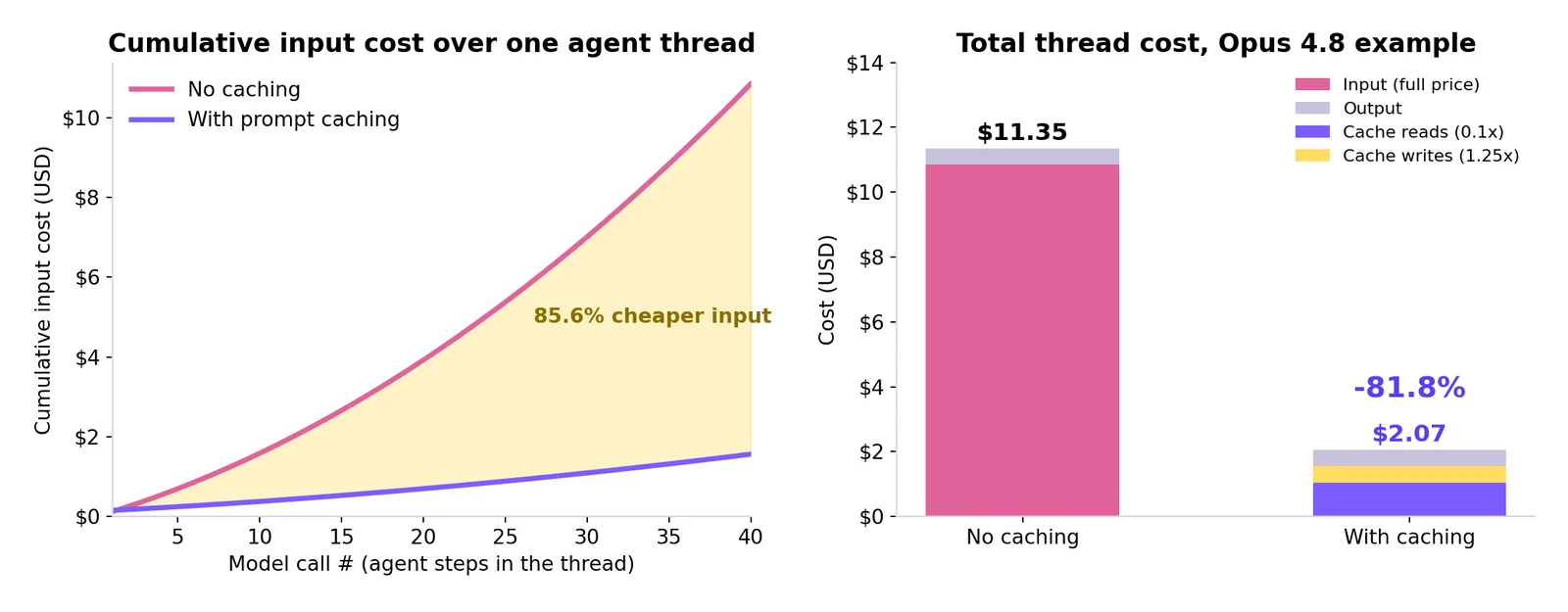
The same thread, priced both ways on Opus 4.8. The gap widens with every step, because caching turns quadratic re-reading into a 0.1× line item.
There is a second, underrated benefit: latency. Cached tokens skip the prefill computation, so time-to-first-token on a 80K-token context drops from many seconds to roughly the cost of processing the new suffix. For an agent making 40 sequential calls, that compounds into minutes of wall-clock time saved per task.
3. The catch: caches are fragile and impatient
If the discount is 10×, why doesn't everyone just turn it on and walk away? Because prompt caches come with two sharp constraints:
- Exact prefix match. The cache resumes only if the new request is byte-identical up to the cached point. Change one character in the system prompt, reorder a tool definition, inject a timestamp, and you recompute everything at full price.
- Short lifetime. Anthropic's standard cache entry lives about 5 minutes and refreshes on every hit. Go quiet for a few minutes and the cache is gone; the next call pays a full re-write of the whole prefix.
This means prompt caching is not a checkbox. It is a design constraint that has to shape your entire agent architecture. Most of the interesting engineering in Viktor's model layer exists to answer one question: how do we keep the prefix byte-stable, and what do we do in the seconds before a cache dies?
4. How Viktor's thread engine is designed around the cache
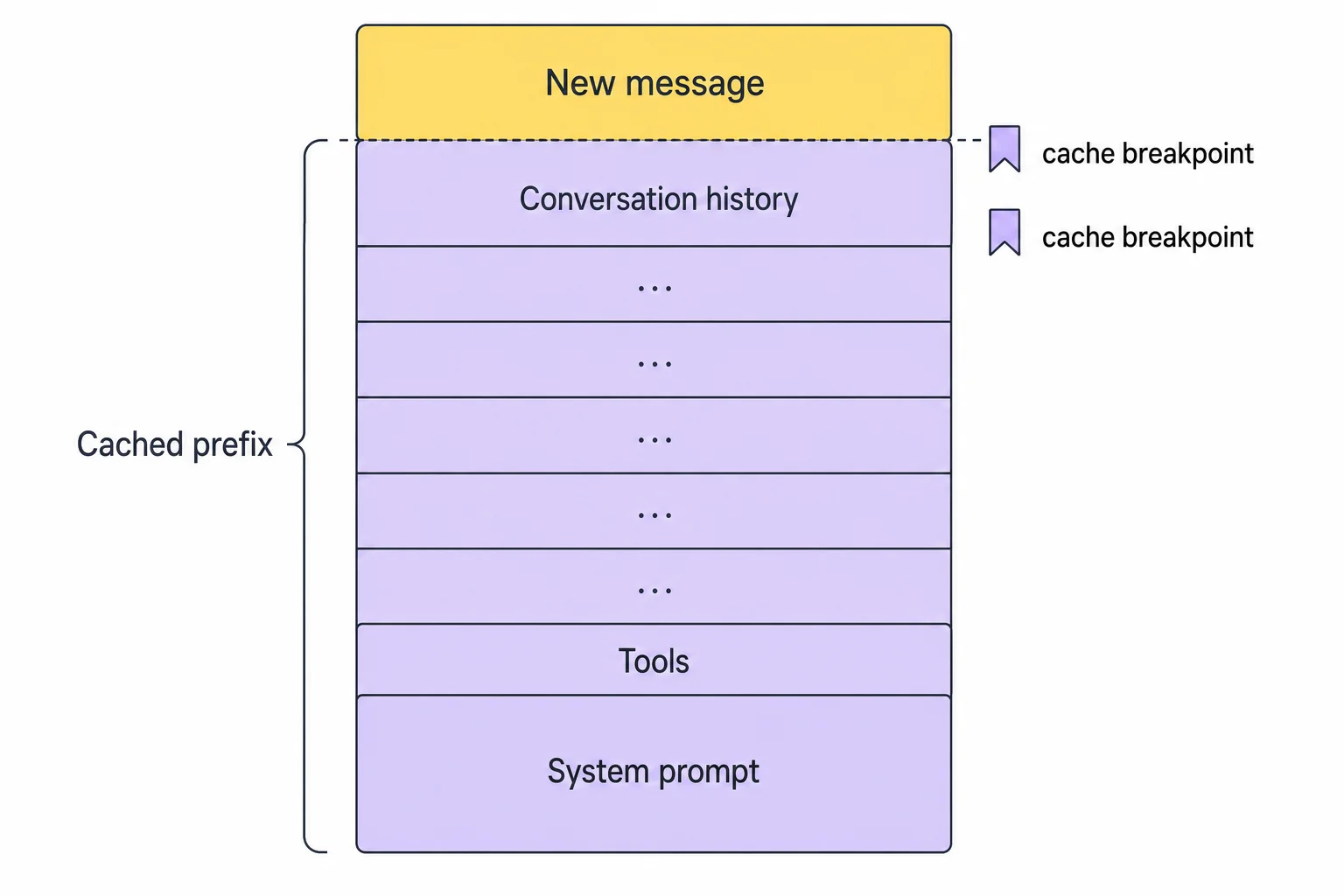
The anatomy of a Viktor model call. Everything below the newest message is a stable, cached prefix.
4.1 A toolset that never changes: the SDK decision
Viktor connects to 3,200+ tools. The standard way to expose tools to a model is to inject every tool's JSON schema into the request, and at this scale that simply does not work. The schemas alone would blow past context limits, and tool-calling accuracy degrades long before you get there: models get measurably worse at picking the right tool as the toolset grows. So you need some form of dynamic tool discovery, where only the relevant tools are surfaced at any given moment. But here caching bites back: tool definitions sit at the very front of the prompt, before the conversation. Load discovered tools into the request dynamically and the prefix changes at position zero, invalidating the thread's cache every time the toolset shifts.
So dynamic tools have to be wrapped behind something stable. One option is a single generic dispatch tool that accepts a payload dict you parse out yourself. Viktor goes a step further: the model writes real code, and every integration is exposed as a plain function in an SDK inside the agent's sandbox. The model sees a small, fixed set of native tools (run a shell command, read and edit files, send a Slack message, and a handful of others). Calling Stripe or Linear is not a tool schema in the prompt; it is three lines of Python the model writes in a script. (We wrote more about scaling tool access in What Breaks When Your Agent Has 100,000 Tools.)
# The model does not get a "stripe_list_subscriptions" tool schema.
# It gets a bash tool, and writes this instead:
from sdk.tools.stripe_tools import list_subscriptions
#
subs = await list_subscriptions(status="active", limit=100)4.2 The thread is an append-only log
There is a stricter way to state the exact-prefix rule, and it is worth elevating to a design principle: a cache-friendly thread is an append-only log. Nothing that has been sent may ever be edited, reordered, or deleted; the only legal operation is appending to the end. Viktor's thread engine treats this as a hard invariant, and it is more constraining than it sounds:
- No clock in the system prompt. Injecting the current timestamp at position zero would invalidate every cache on every call. Instead, each turn carries its own fixed timestamp when it is appended, which never changes afterwards, and the model derives the current time from the newest one.
- Mid-thread changes arrive as messages, not edits. When a user connects a new integration or updates an instruction halfway through a thread, we cannot rewrite the system prompt of the live thread. The update has to be appended as a new message, and the system prompt only reflects it in threads that start afterwards.
Living with these constraints is the price of the 0.1× line item. The payoff is that cache safety becomes structural: there is no code path that can accidentally mutate history, so there is no code path that can accidentally torch a warm cache.
4.3 Cache breakpoints that ride the conversation
Anthropic's cache is explicit: you mark positions in the prompt with cache_control breakpoints, and everything up to a marker is cached as one prefix. Viktor's model layer places these markers in three kinds of places:
- on the system prompt block (since the system prompt is stable for a given user, this caches it across threads, not just within one),
- on the last tool definition (which caches the whole tool block, since tools precede messages),
- on the last two user-role messages in the conversation.
def add_cache_control(messages):
"""
Adds cache_control to the second to last and last user messages.
This way we can assume that the earlier messages didn't change
so caching will work.
"""
user_messages = [i for i, msg in enumerate(messages) if msg["role"] == "user"]
indices_to_modify = user_messages[-2:]
#
for index in indices_to_modify:
# ... find the last text/tool_result block in that message ...
item["cache_control"] = {"type": "ephemeral"}4.4 Compaction that reuses the thread's own cache
Caching makes re-sending cheap, but it does not make context infinite, and it does not make a 200K-token transcript pleasant for the model to reason over. Like every serious agent runtime, Viktor compacts long threads: older turns get summarized into a dense recap, and the live window keeps only the summary plus recent messages.
The naive way to summarize a thread is to spin up a separate call: fresh prompt, "summarize this conversation", paste the transcript. That call shares no prefix with the live thread, so you pay full price to re-process the entire history you were so carefully caching.
Viktor instead runs compaction inside the thread's own cache. The summarization request is the live thread, byte-for-byte, with exactly one thing appended: a final user message containing the compaction instructions.
def build_summary_request_messages(ai_messages, plan, *, use_full_history):
if use_full_history:
summary_messages = list(ai_messages) # the live thread, unchanged
#
summary_messages.append({
"role": "user",
"content": [{
"type": "text",
"text": COMPACTION_PROMPT,
SKIP_CACHE_CONTROL_KEY: True, # don't move the cache breakpoints
}],
})
return summary_messages- The compaction prompt is excluded from cache breakpoints. Anthropic allows four breakpoints per request and the thread already spends all four. The appended instruction is marked to be skipped so it does not waste a breakpoint on a message that exists only in this one side-call.
- The summarizer is called with the same tool definitions as the main loop, with
tool_choice="none". Tools are part of the prefix; drop them and nothing matches. Sending the identical tool block while forbidding tool use keeps the prefix intact and still forces a text-only summary. - The full history is sent, not a trimmed slice. Counter-intuitively, sending more is cheaper here: the full transcript is a 0.1× cache read, while a trimmed slice would be a cache miss billed at 1×.
In our example thread, summarizing 60,000 tokens of history as a fresh standalone call on Opus 4.8 would cost about $0.30 of input. As an in-cache call it costs about $0.03. That number changes which model you should summarize with. The instinct is to ship the transcript to a cheap model: on something like Gemini Flash 3.5, at around $0.30 per million input tokens, the same 60,000 tokens cost about $0.02 fresh, roughly the same as the cached Opus read. But Opus already holds the thread, including its own thinking traces, in cache; the cheap model starts cold, has to re-derive all of that reasoning at output prices, and writes a noticeably worse summary that then becomes permanent context for the rest of the thread. With caching, the frontier model's summary costs about the same as the budget model's worse one. The choice makes itself.
4.5 Never compact a hot thread
Compaction has a hidden cost beyond the summarizer call itself: it rewrites history. The moment a summary replaces older turns, the prompt prefix changes near the beginning, and the entire cache for that thread is dead. The next model call re-writes everything at 1.25×.
So Viktor is deliberately lazy while a conversation is active. During a live exchange, compaction only triggers once the conversation passes roughly 50,000 tokens, on top of the ~8,000-token stable prefix of system prompt and tools. Below that, the thread just keeps riding its warm cache. A mid-conversation compaction would have to claw back its cache-invalidation cost before it saved anything, and on an active thread it usually would not.
4.6 Compact aggressively, right before the cache dies
The flip side: the moment a thread goes quiet, the calculus inverts. Anthropic's cache entry expires about 5 minutes after its last use. Once it is cold, the next message pays a full prefix re-write anyway, so there is no longer anything to protect. The best moment to compact is therefore just before the cache goes cold: late enough that the user is probably done, early enough that the summarization call itself still rides the warm cache at 0.1×.
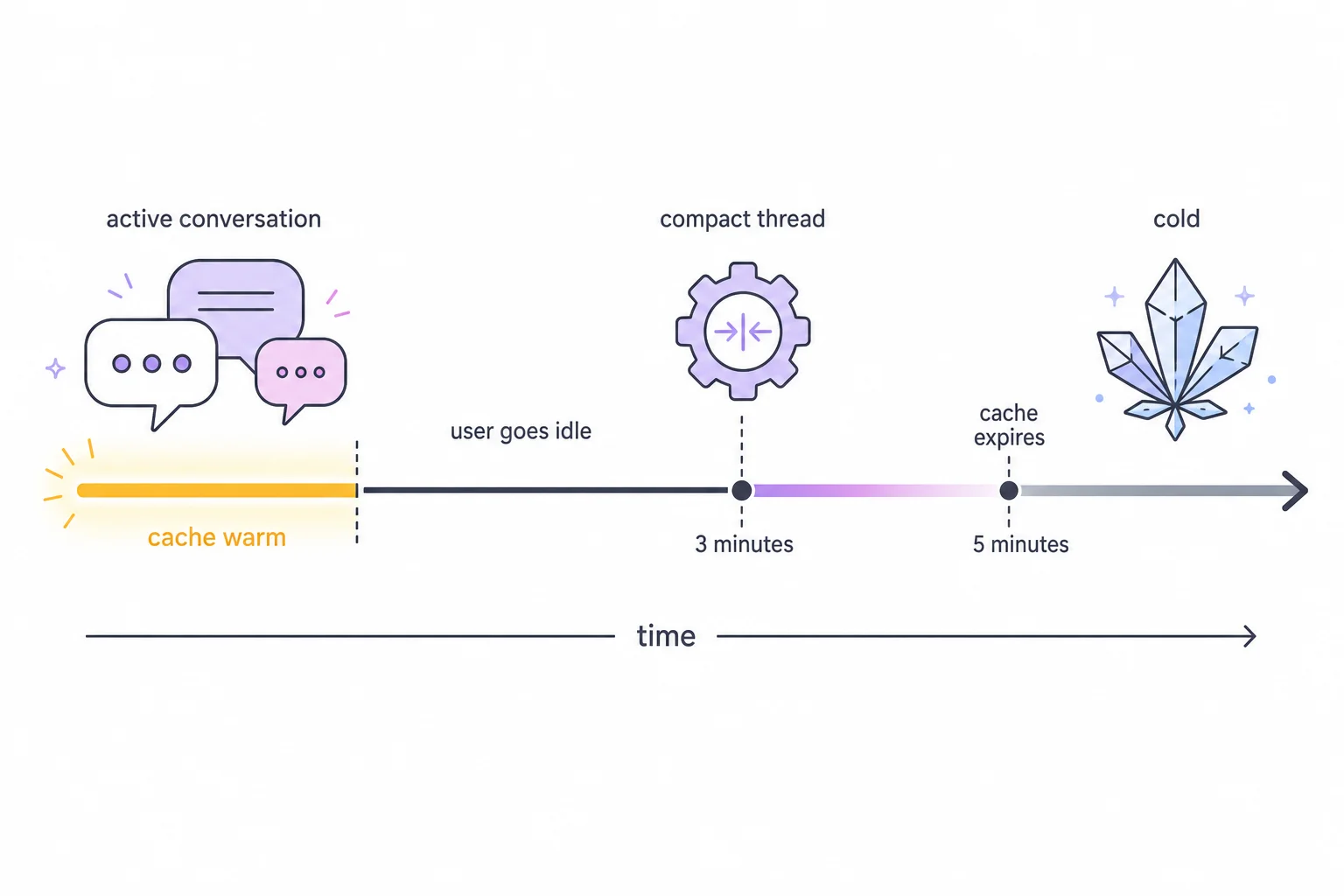
The 2-minute window that matters: Viktor compacts at minute 3 of idleness, inside the warm-cache window that closes at minute 5.
Mechanically, every reply registers a delayed summary signal 3 minutes in the future. If the user (or the agent) sends anything new, the signal is cleared and re-registered; an active thread never fires it. If the thread stays quiet, a background worker picks the signal up and compacts at a much lower bar: a quiet thread is compacted once it passes roughly 16,000 conversation tokens, versus roughly 50,000 for an active one. Compaction is never an amputation, though. The most recent ~13,000 tokens of conversation always survive verbatim, and only what lies beyond them is folded into the summary, so a thread that goes cold restarts at roughly 25,000 tokens (stable prefix, summary, recent verbatim turns) instead of 60,000 or more.
SUMMARY_DELAY_MINUTES = 3 # fire inside the 5-minute cache TTL
#
KEEP_AT_LEAST_NUM_TOKENS_REMAINING = 13_000 # always survives verbatim
MIN_TOKENS_TO_SUMMARIZE = 35_000 # hot: compact past ~50K
MIN_TOKENS_TO_SUMMARIZE_DELAYED = 3_000 # idle: compact past ~16K
#
# on new activity:
await check_and_clear_summary_signal(thread_id, user_id)4.7 Different providers, different clocks
Everything above describes Anthropic's caching model: explicit breakpoints, a 1.25× write premium, a 5-minute sliding TTL. OpenAI's cache behaves differently, and Viktor's model layer adapts per provider rather than pretending one set of rules fits all:
- Anthropic: explicit
cache_controlmarkers, placed as described. The 3-minute idle compaction clock is tuned against the 5-minute TTL. - OpenAI: caching is automatic on prefixes beyond ~1K tokens, there is no write premium, and cached reads are also billed at 0.1× on current GPT-5.x models. There are no breakpoints to place; each request just carries a
prompt_cache_keyderived from the thread, so the provider routes consecutive calls of the same thread to the same cache shard. The convenience cuts both ways: with no explicit control, cache hit rates are sometimes lower in practice than with Anthropic's opt-in scheme. And since OpenAI's cache eviction is looser (minutes to an hour, depending on load) and a cold start carries no 1.25× penalty, the just-before-cold compaction timing matters less; the high hot-thread threshold matters more. - Self-hosted and edge providers: some only hit their prefix cache when consecutive requests land on the same replica. For those, Viktor pins threads to a replica with a session-affinity header keyed by the same cache key. A cache that exists but is never routed to is worth nothing.
The thread engine treats all of this as a provider adapter concern. The agent loop upstream is identical; what changes per provider is where markers go, what gets stripped, which affinity hints are sent, and how the compaction scheduler weighs "cache about to die" against "thread getting long".
5. What this adds up to
None of these decisions is exotic in isolation. Together they form a posture: treat the provider's cache as a first-class system component with its own lifecycle, not as a billing optimization you sprinkle on at the end.
- The SDK-instead-of-tool-loading decision keeps the prefix small and byte-stable forever.
- Treating every thread as an append-only log makes cache safety a structural guarantee instead of a discipline.
- Breakpoints riding the conversation extend the cache with every agent step, with a spare marker absorbing message merges.
- In-cache compaction makes thread maintenance ride the same cache as the thread itself.
- The hot/idle threshold split (~50K vs ~16K) means we never pay cache invalidation while the cache is earning its keep, and never waste a dying cache's last warm minutes.
- Per-provider adapters make the same thread engine cache-optimal on Anthropic, OpenAI, and edge inference.
On our running Opus 4.8 example, that is the difference between $11.35 and $2.07 per thread, an 81.8% reduction, before counting the latency win on every single step. At the scale of an AI employee handling thousands of threads a day, it is the difference between a product with healthy unit economics and one that loses money every time a user asks a hard question.
If you are building an agent, the short version: put everything stable first and treat the thread as an append-only log; never inject timestamps or per-request noise into the prefix; summarize inside the cache, not beside it; compact when threads go idle, not while they are hot; and learn each provider's cache lifetime, because the best moment to do expensive maintenance is the minute before the cache dies.
The code shown in this post is lightly trimmed from our production thread engine. Numbers are based on Claude Opus 4.8 list pricing at the time of writing.
Related reading: What Breaks When Your Agent Has 100,000 Tools · What Is an AI Coworker? · How to Optimize Viktor Credits